先说结论:本地 AI 已经能打了。
不是「勉强能用」那种打,是「真的挺能打」那种打。
我在自己的 MacBook Pro 上,把 6 个主流本地模型全跑了一遍,包括多轮对话、真实工具调用、写文件验证……
数据是真实的,坑是踩过的,废话不多,进正题。
🖥️ 测试环境
📦 硬件
- MacBook Pro M5 Pro — Apple Silicon,arm64 架构
- 64GB 统一内存(Unified Memory)
- 这块内存 CPU 和 GPU 共享,模型可以吃满全部 64GB
🔧 软件
- macOS Sequoia
- mlx_lm 0.31.3 — Apple 官方 MLX 推理框架
- OpenCode — 本地 IDE AI 助手(类似 Cursor,但跑本地模型)
什么是 Unified Memory(统一内存)?
普通电脑 CPU 和 GPU 各有自己的内存,中间传数据要「搬家」,慢且浪费。苹果芯片把两者合并成一块,模型直接住进去,不用搬,快很多。
64GB 意味着可以同时塞进去一个 28GB 的模型,还有 36GB 跑系统和其他程序。
🤖 6 个参赛选手
这次测了 6 个模型,来自阿里和 Google 两大阵营。
什么是量化(Quantization)?
就是给模型「减肥」。原版模型每个参数用 16bit 存,4bit 量化就压缩到 1/4 大小。代价是精度稍微损失一点,但速度快、内存省。
类比:原版是 FLAC 无损音乐,量化版是 MP3——大多数时候听不出区别,但文件小多了。
模型名称 | 出品方 | 占用内存 | 精度 | 特点 |
Qwen3.6-27B-8bit | 阿里 | 28 GB | 8bit | 精度最高,8bit 接近原版 |
Qwen3.6-27B-4bit | 阿里 | 14 GB | 4bit | 同款压缩版,省一半内存 |
Qwen3.6-35B-A3B | 阿里 | 19 GB | 4bit | MoE 架构,最高效 ⭐ |
Gemma4-E4B-BF16 | Google | 14 GB | BF16 | Google 出品,全精度 |
Gemma4-E4B-4bit | Google | 3.9 GB | 4bit | 最轻量,速度最快 🚀 |
Gemma4-31B-Uncensored | 社区 | 18 GB | 4bit | 无审查版,创作自由 |
※ 内存越小不代表越差,MoE 架构用 19GB 却是综合最强
什么是 MoE(混合专家)?
普通模型每次推理都全员出动,MoE 模型内部有很多「专家小组」,每次只调用其中最合适的几个。
结果:35B 参数的模型,实际计算量只用了一小部分,速度反而比 27B 还快。
📋 怎么测的
4 个场景,每个模型都要过一遍。测试脚本全自动跑,数据客观可复现。
场景 A · 多轮对话(3轮连续)
连续提 3 个问题,考察模型能不能记住上下文,以及第 2、3 轮能加速多少。
- 问 1:用一句话介绍自己
- 问 2:你支持哪些编程语言?
- 问 3:Python 和 JS 最大区别是什么?
场景 B · 工具调用——列出目录
让模型去查 /tmp 目录有什么文件,然后总结。模型必须先调用工具拿到结果,再回答。
场景 C · 工具调用——执行命令
让模型执行 uname -a 命令并解读结果。测试模型能不能正确调用 bash 并理解系统信息。
场景 D · 工具调用——写文件 + 验证
写入内容到文件,再读取验证。两步工具调用串联,考察模型的连续推理能力。
什么是工具调用(Function Calling)?
普通 AI 只会「说话」。工具调用让 AI 能「动手」——调用程序、读文件、执行命令。
类比:工具调用就是给 AI 装上了手和脚,它不只是嘴上说「我帮你查一下」,而是真的去查了,把结果拿回来再告诉你。
数据里经常出现的 token 是什么?
Token 是 AI 理解文字的最小单位。1 个英文单词 ≈ 1 token,1 个汉字 ≈ 1.5 token。
我们测试时每次给模型发 9000~10000 个 token(相当于 6000 多汉字的系统提示词 + 对话)。
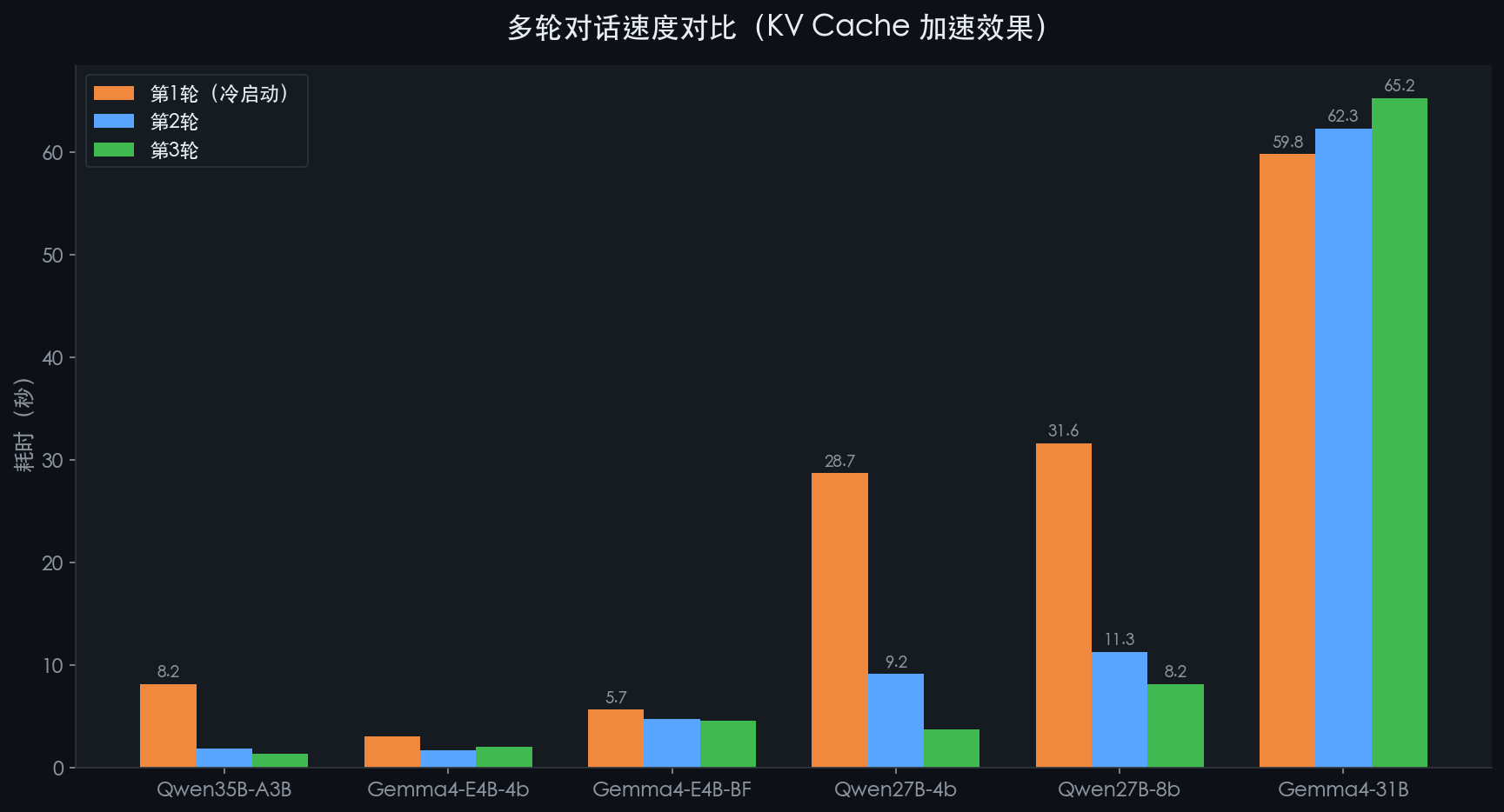
⏱️ 场景 A:多轮对话速度对比
先看数字,再说感受。
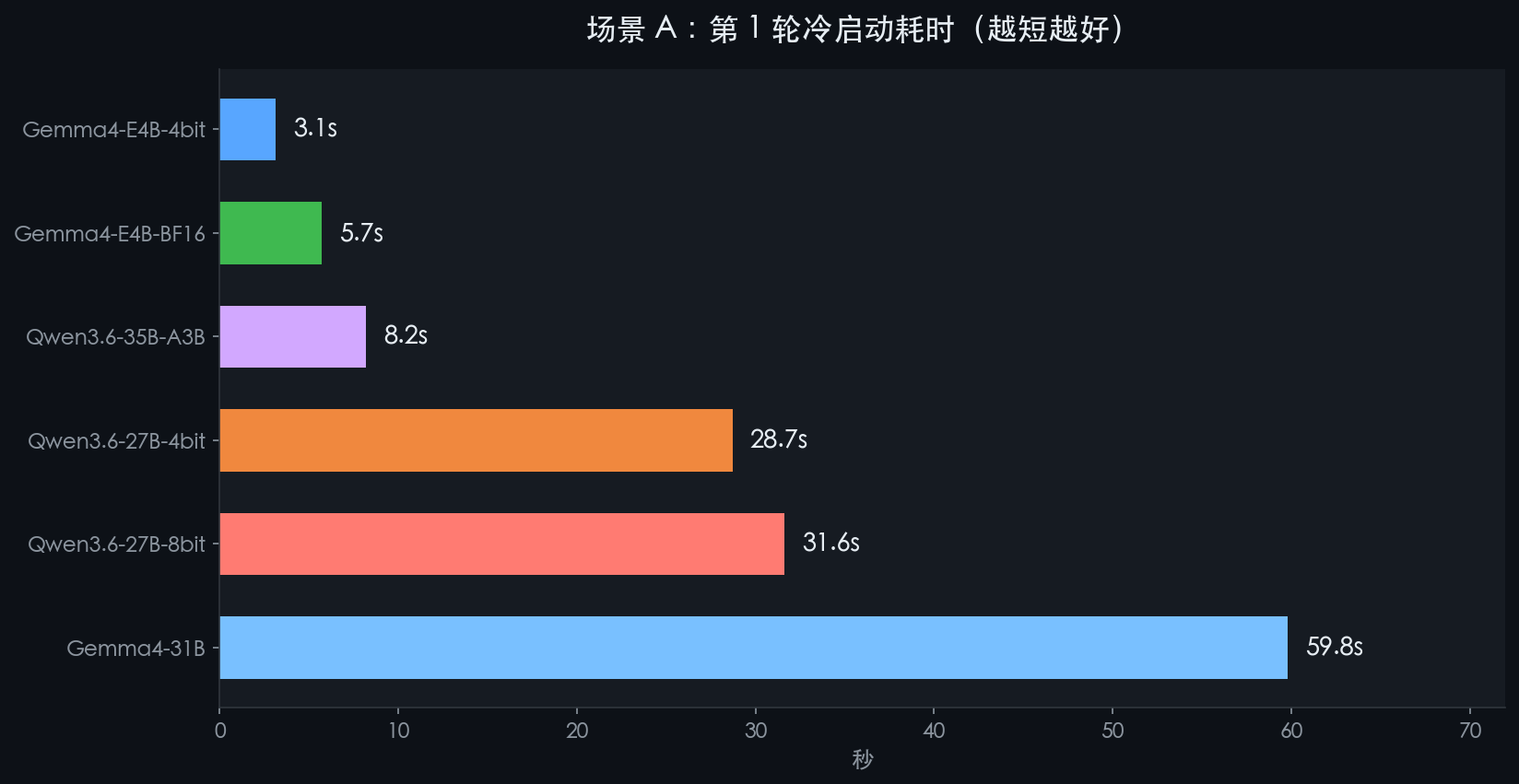
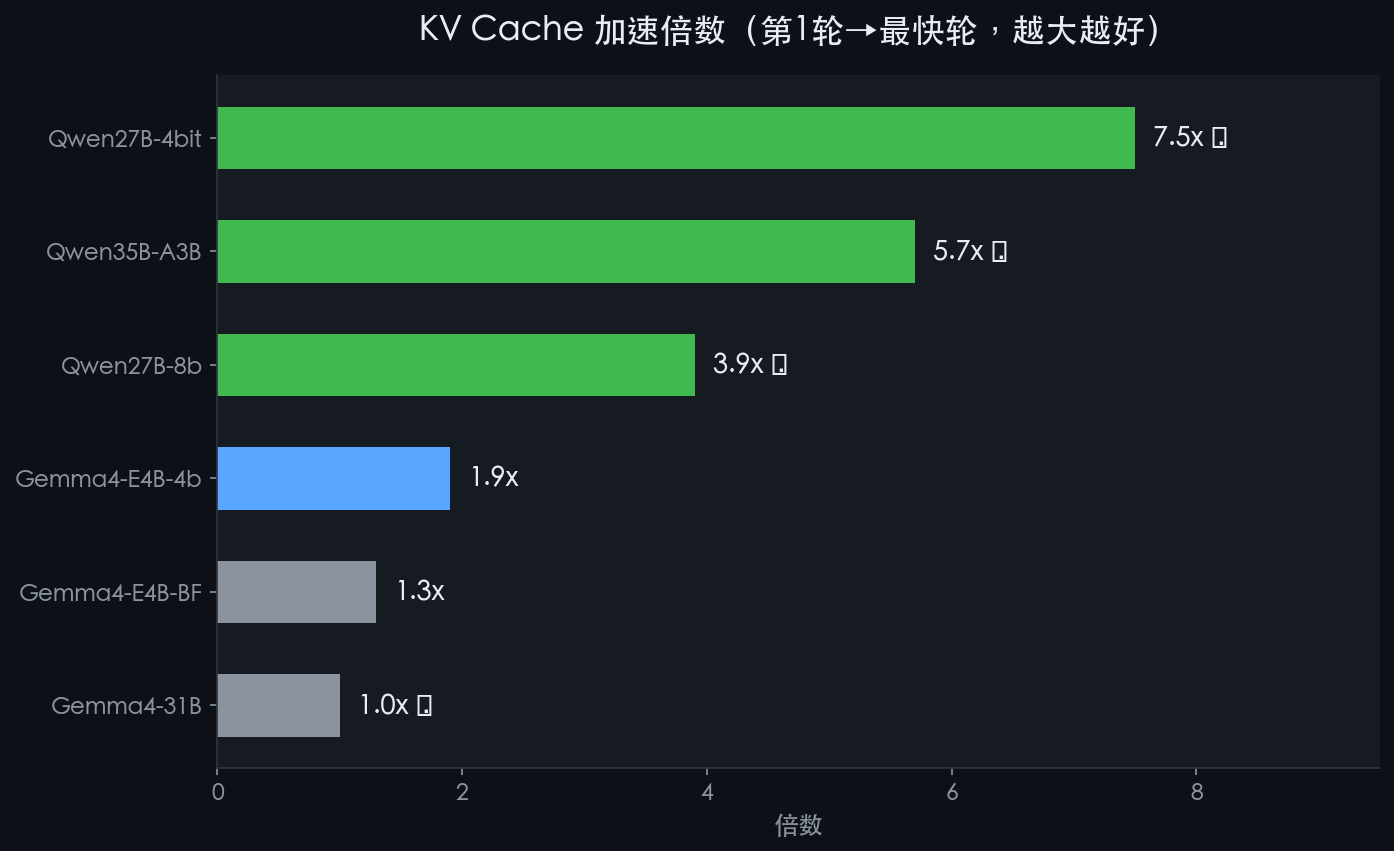
模型 | 第1轮(冷启动) | 第2轮 | 第3轮 | 最高加速比 |
Qwen3.6-35B-A3B | 8.2s | 1.9s | 1.4s | 🏆 5.7x |
Gemma4-E4B-4bit | 3.1s | 1.7s | 2.1s | 1.9x |
Gemma4-E4B-BF16 | 5.7s | 4.8s | 4.6s | 1.3x |
Qwen3.6-27B-4bit | 28.7s | 9.2s | 3.8s | 🥈 7.5x |
Qwen3.6-27B-8bit | 31.6s | 11.3s | 8.2s | 3.9x |
Gemma4-31B | 59.8s | 62.3s | 65.2s | 1.0x 😅 |
※ 第1轮慢是正常的,模型第一次处理长前缀需要时间;第2轮开始命中 KV Cache 会大幅加速
什么是 KV Cache(缓存加速)?
第 1 轮要处理 9000 多个 token 的系统提示词,很慢。但模型会把这部分「记忆」存下来,第 2、3 轮直接复用,只处理新增的几十个 token。
类比:第一次背课文要 30 分钟,背完之后复述只要 1 分钟。KV Cache 就是这个「已经背熟了」的状态。
Qwen35B 第 2 轮加速 5.7 倍,Qwen27B-4bit 加速 7.5 倍。
🔧 场景 B/C/D:工具调用速度对比
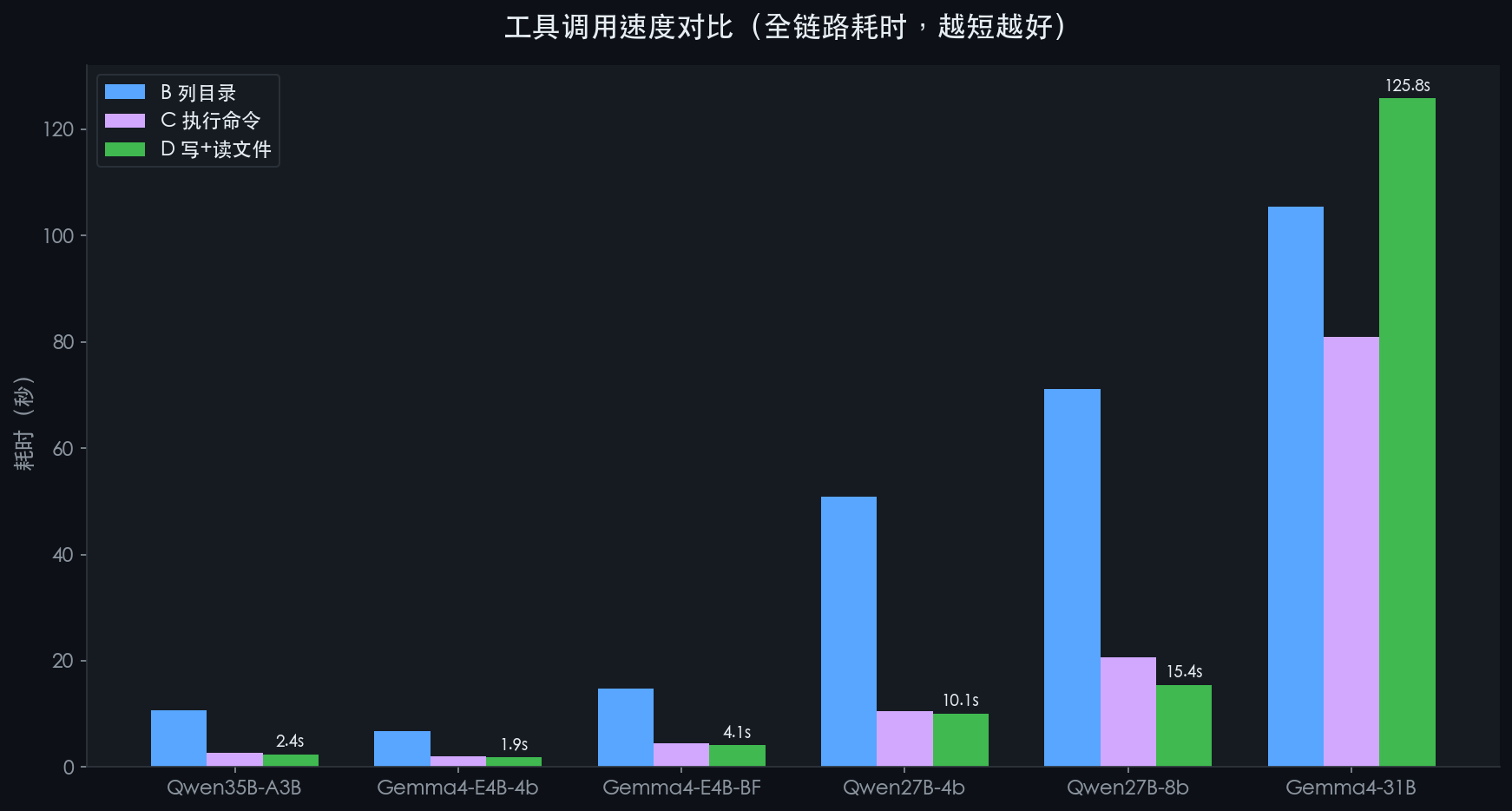
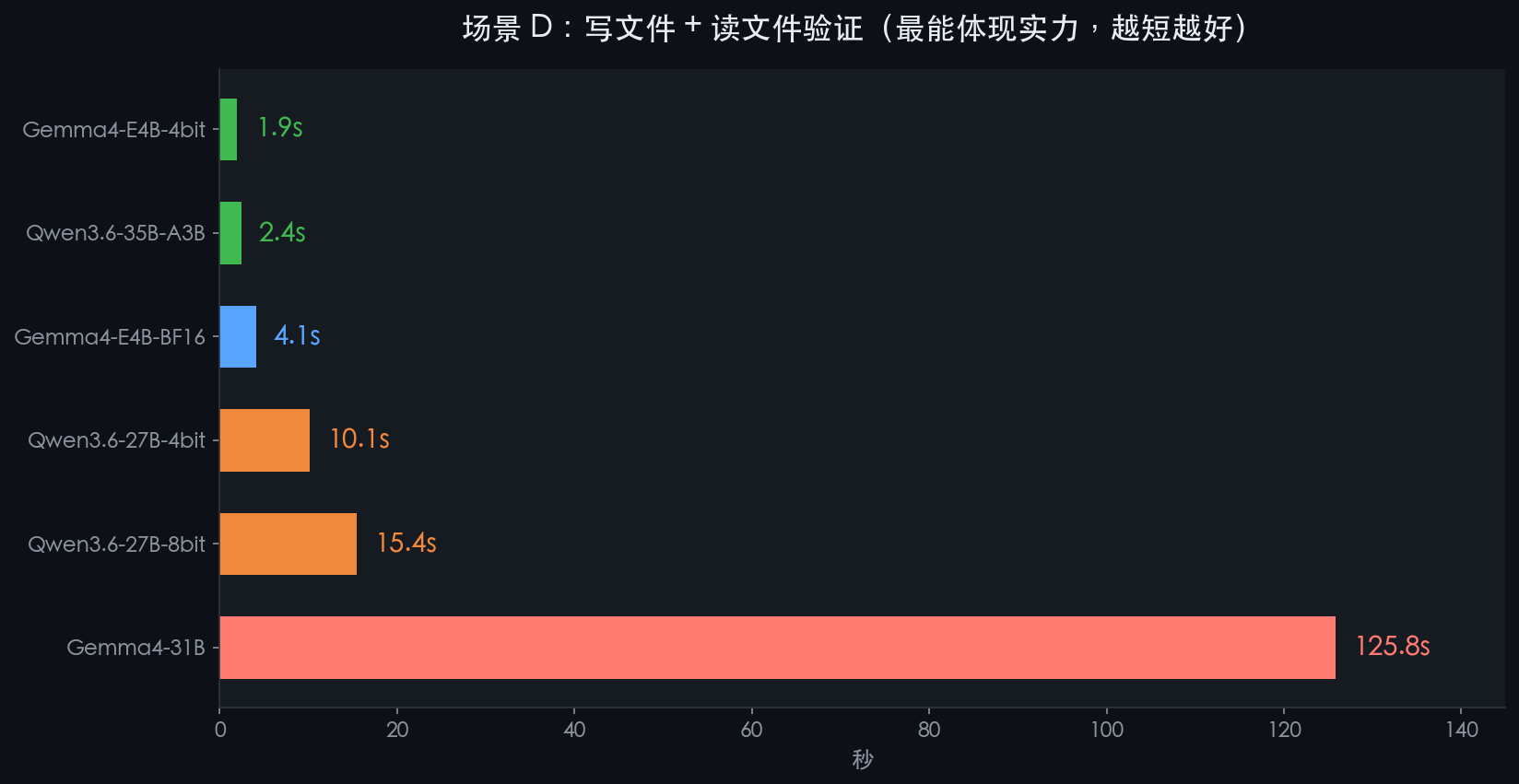
这个更能体现实际使用体验——调用工具、拿结果、再回答,全链路多久?
模型 | B 列目录 | C 执行命令 | D 写+读文件 |
Qwen3.6-35B-A3B | 10.7s | 2.7s | 🏆 2.4s |
Gemma4-E4B-4bit | 6.8s | 2.0s | 🥈 1.9s |
Gemma4-E4B-BF16 | 14.8s | 4.5s | 4.1s |
Qwen3.6-27B-4bit | 50.8s | 10.5s | 10.1s |
Qwen3.6-27B-8bit | 71.2s | 20.7s | 15.4s |
Gemma4-31B | 105.5s | 81.0s | 125.8s 😩 |
※ 每个场景包含从用户提问到模型最终回答的全部时间
🎬 真实工具调用长什么样?
以场景 D 为例,看看 Qwen35B 是怎么完成「写文件 + 验证」这个任务的。全程 2.4 秒,3 个步骤,零失误。
👤 用户
帮我在 /tmp/mlx_test_output.txt 写入内容 'Hello from MLX model!',然后读取验证。
🤖 模型 Step 1(1.0s)
「我来帮你完成这个任务。」
调用工具:write_file(path="/tmp/mlx_test_output.txt", content="Hello from MLX model!")
⚙️ 系统执行(真实写入)
返回:Written 21 bytes to /tmp/mlx_test_output.txt🤖 模型 Step 2(0.8s)
「文件写入成功(21 字节)。现在读取验证:」
调用工具:read_file(path="/tmp/mlx_test_output.txt")
⚙️ 系统执行(真实读取)
返回:Hello from MLX model!🤖 模型 Step 3(0.6s)
✅ 完成!文件 /tmp/mlx_test_output.txt 已成功写入并验证,内容为:Hello from MLX model!
整个过程模型真的在你电脑上执行了文件操作,不是假装——这就是「工具调用」的意义。
💬 6 个模型怎么回答同一个问题?
问题:用一句话介绍自己
同一个系统提示词,看谁更「有自我」
Qwen3.6-35B-A3B ⭐
你好!我是 OpenCode,一个专注于代码编辑、文件操作和系统任务的专家级 AI 编程助手,旨在通过主动使用工具来高效协助你完成各种开发工作。
Qwen3.6-27B-8bit
你好!我是 OpenCode,一个专业的 AI 编程助手,可以直接在 IDE 中帮你读写代码、运行命令和调试问题。
Qwen3.6-27B-4bit
你好!我是 OpenCode,你的 AI 编程助手。👨💻
Gemma4-E4B-BF16
你好,我是一个嵌入在 IDE 中的专家 AI 编码助手,可以帮助你进行代码编写、调试和管理。
Gemma4-E4B-4bit
你好!我是一个嵌入在 IDE 中的专家 AI 编码助手,可以帮助你进行各种编码相关的任务,比如阅读代码、调试、生成代码等。
Gemma4-31B-Uncensored
你好!我是 OpenCode,一个集成在 IDE 中的专家级 AI 编程助手,旨在通过精准的代码辅助提升你的开发效率。
再看:Python 和 JavaScript 最大区别是什么?
这道题考察知识准确性和表达简洁性
Qwen3.6-35B-A3B ⭐
Python 使用缩进定义代码块且是动态强类型,强调代码可读性;而 JavaScript 使用大括号定义代码块,是动态弱类型,主要用于 Web 前端交互,两者在类型系统、作用域规则(var/let/const)和异步处理机制上也有显著差异。
Qwen3.6-27B-8bit
Python 是解释型、强类型、动态类型语言,以简洁易读著称,主要用于后端、数据科学和 AI;JavaScript 是基于原型、弱类型、动态类型语言,是 Web 前端开发的唯一原生语言,也可通过 Node.js 用于后端。
Qwen3.6-27B-4bit
Python 是静态缩进的解释型语言,强调代码可读性和简洁性;JavaScript 是大括号语法的动态语言,主要用于 Web 前端。
Gemma4-E4B-4bit
最大的区别在于运行环境和类型系统:Python 是解释型高层次语言,强调可读性和简洁性,并且是动态强类型;JavaScript 是动态弱类型语言,主要用于 Web 前端交互。
Gemma4-E4B-BF16
Python 和 JavaScript 的最大区别在于设计哲学和主要应用场景:Python 是通用高层次语言,强调可读性;JavaScript 主要用于 Web 前端交互。
Qwen35B 和 Qwen27B-8bit 回答最完整,Gemma4-E4B-4bit 虽然只用 3.9GB,回答质量不输大模型。
💀 踩了哪些坑(这才是最有价值的部分)
从「一跑就崩」到「全部通过」,中间修了 4 个大坑。
⚠️ 坑 1:多轮对话第 2 轮直接 OOM 崩溃
现象:第 1 轮正常,第 2 轮 Metal GPU 直接内存溢出,进程挂掉。
根因:OpenCode 每次请求都注入了 58,253 个 token 的系统提示词(相当于 3.8 万汉字!)。第 1 轮占满了大量 KV Cache,第 2 轮再加上对话历史,超出 64GB 内存上限,直接崩。
修复:加上 --prompt-cache-bytes 8589934592 参数,限制 KV Cache 最多用 8GB。修复后第 2 轮从 3 分钟 → 2 秒,加速 110 倍。
⚠️ 坑 2:Gemma4-E4B-4bit 架构不兼容,秒崩
现象:服务器启动成功,但一发请求立刻报错:「Received 126 parameters not in model」。
根因:这个模型是用旧版 mlx_lm 转换的,滑动注意力层的权重格式和新版(0.31.3)不兼容,126 个参数无处安放,直接报错退出。
修复:删掉旧模型,从 BF16 版本重新量化。新模型 3.9GB,完美兼容,全部测试通过。
⚠️ 坑 3:Gemma4-E4B-BF16 第 3 轮回复全是空的
现象:Turn 3 输出了 400 个 token,但内容为空字符串。
根因:Gemma4 的 chat_template.jinja 文件有一个逻辑:只要检测到 system 消息,就自动开启 thinking(思考)模式,400 个 token 全被 <think\>...<\/think\> 占满,没有空间输出真正的回答。
修复:启动参数加 --chat-template-args '{"enable_thinking":false}',强制关闭思考模式。修复后 Turn 3 从 16秒空输出 → 0.3秒正常回答。
⚠️ 坑 4:Gemma4-31B 启动报错,参数不支持
现象:服务器启动失败,报错「unrecognized arguments: --prompt-cache-bytes」。
根因:Gemma4-31B 用的是 mlx_vlm.server(视觉语言模型服务器),和普通的 mlx_lm.server 参数不一样,--prompt-cache-bytes 是后者的参数,前者根本不认识。
修复:改用 mlx_vlm.server 的专属参数 --max-kv-size 32768,修复后全部通过。
🏆 怎么选?一句话推荐
🚀 速度第一 → Gemma4-E4B-4bit
3.9GB,Turn 1 仅 3 秒,工具调用最快 1.9 秒完成。内存占用极低,可以和其他大模型并行跑。
⭐ 质量+速度 → Qwen3.6-35B-A3B
19GB MoE 架构,回答质量最好,工具调用全场景最稳定。Turn 2 加速 5.7x,多轮对话极流畅。
🎯 精度优先 → Qwen3.6-27B-8bit
28GB,8bit 量化接近原版精度。适合对准确性要求高的任务,代价是冷启动慢(~32秒)。
🎨 无限制 → Gemma4-31B-Uncensored
无内容审查,适合创意写作。缺点是每轮约 60 秒,不适合需要快速交互的场景。
🎯 总结
- 本地 AI 真的可用了,不是玩具——工具调用、多轮对话、文件操作,全部通过
- Gemma4-E4B-4bit 只有 3.9GB,但性能让很多大模型汗颜
- Qwen3.6-35B-A3B MoE 架构是性价比之王,19GB 打出了 35B 的效果
- KV Cache 的加速效果非常明显,第 2 轮以后基本都是秒回
- 踩坑不可避免,但每个坑都有明确的修复方案
- 苹果 M 系列芯片跑本地 AI 的体验,在 2026 年已经相当成熟
隐私、离线、免费、可定制——本地 AI 的时代正在到来。 以上所有测试数据均来自真实测量,脚本开源,可自行复现。
测试时间:2026-05-21 | 总耗时:14分52秒 | 数据文件:mlx-test-results-20260521-183949.json
—— 黑粉科技 · 让AI成为你的超能力 ——hyphentech.top
分享到: